
Introduction:
Voice AI is Speech Datasets revolutionizing human interaction with technology, encompassing virtual assistants like Siri and Alexa, automated transcription services, and real-time language translation. Central to these innovations is a vital component: high-quality speech datasets. This article examines the significance of speech datasets in the progression of voice AI and their necessity for developing precise, efficient, and intelligent speech recognition systems.
The Significance of Speech Datasets in AI Development
Speech datasets consist of collections of recorded human speech that serve as foundational training resources for AI models. These datasets are crucial for the creation and enhancement of voice-driven applications, including:
- Speech Recognition: Facilitating the conversion of spoken language into written text by machines.
- Text-to-Speech: Enabling AI to produce speech that sounds natural.
- Speaker Identification: Differentiating between various voices for purposes of security and personalization.
- Speech Translation: Providing real-time translation of spoken language to enhance global communication.
Essential Characteristics of High-Quality Speech Datasets
To create effective voice AI applications, high-quality speech datasets must encompass:
- Diverse Accents and Dialects: Ensuring that AI models can comprehend speakers from various linguistic backgrounds.
- Varied Noise Conditions: Training AI to function effectively in real-world settings, such as environments with background noise or multiple speakers.
- Multiple Languages: Facilitating multilingual capabilities in speech recognition and translation.
- Comprehensive Metadata: Offering contextual details, including speaker demographics, environmental factors, and language specifics.
Prominent Speech Datasets for AI Research
Numerous recognized speech datasets play a crucial role in the development of voice AI, including:
- LibriSpeech: A comprehensive collection of English speech sourced from audiobooks.
- Common Voice: An open-source dataset created by Mozilla, compiled from contributions by speakers worldwide.
- VoxCeleb: A dataset focused on speaker identification, containing authentic recordings from various contexts.
- Speech Commands: A dataset specifically designed for recognizing keywords and commands.
How Speech Datasets Enhance AI Performance
Speech datasets empower AI models to:
- Improve Accuracy: Training on a variety of datasets enhances the precision of speech recognition.
- Mitigate Bias: Incorporating voices from diverse demographics helps to eliminate AI bias and promotes equitable performance.
- Facilitate Adaptability: AI models trained on a wide range of datasets can operate effectively across different settings and applications.
- Promote Continuous Learning: Regular updates to datasets enable AI systems to evolve and improve over time.
Challenges in Collecting Speech Data
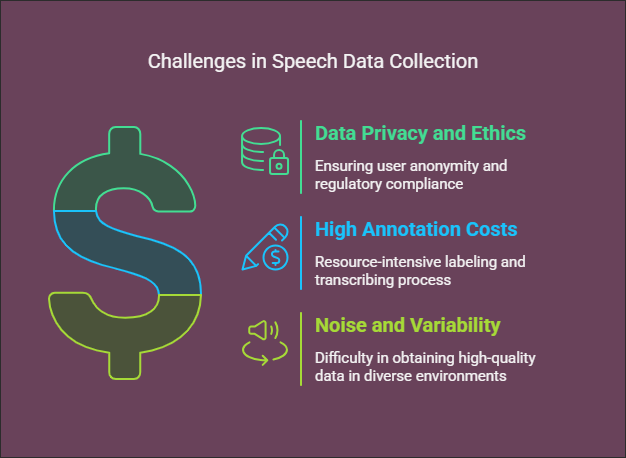
Despite their significance, the collection of speech datasets presents several challenges, including:
- Data Privacy and Ethics: Adhering to regulations and ensuring user anonymity is essential.
- High Annotation Costs: The process of labeling and transcribing speech data demands considerable resources.
- Noise and Variability: Obtaining high-quality data in various environments can be challenging.
Conclusion
Speech datasets play Globose Technology Solutions a critical role in the advancement of voice AI, providing the foundation for speech recognition, synthesis, and translation technologies. By leveraging diverse and well-annotated datasets, AI researchers and developers can create more accurate, inclusive, and human-like voice AI systems.
Comments on “The Importance of Speech Datasets in the Advancement of Voice AI:”